
일본어 한자 외우는법 일본어 12월에 있을 JLPT N4 공부중이라 N5 교재 N4 교재
* 이하는 개인의 주관적 의견입니다. 제 방법은 보통의 체계적인 방법과는 많이 다릅니다.
* JLPT는 공부해본 적 없어서 N4가 어느정도 수준인지 모릅니다. 따라서 방법론이 될 겁니다.
상용한자는 일반적인 한자와 사용법이 다른만큼, 외우는 법도 많이 다릅니다. 한자 한글자씩 공부하는건 의미 없다고 생각합니다.
상용한자 중에서도 자주 쓰이는 한자가 있고, 신문이나 전공서적에서나 나올만큼 어렵고 잘 안쓰이는 한자도 있습니다. 순서대로 외우기 보다는, 자주 쓰이는 한자부터 해 나가면 좋습니다. 대략 1000자 전후로 해서 평범한 문장은 문제 없이 읽고 쓸 수 있게 되며, 1500자 정도 되면 소설책 읽으면서도 크게 어렵지 않을 겁니다.
정리.
1. 사용 빈도 순으로 공부 할 것. (AI한테 상용한자 사용 빈도순으로 정리해달라고 하면 편함)
2. 공부하는 문제집의 지문을 보면서 한자를 정리할 것. 정리는 단어 단위로.
(예시)
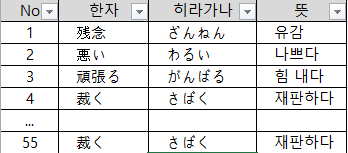
이런식으로 엑셀을 이용해서 정리 해 두면 좋습니다. 만약 한 번 기록 했는데, 잊어버린 단어가 있다면 다시 기록합니다. (위의 4번과 55번 처럼) 그럼 나중에 필터 이용해서 정리하면 여러번 적힌 단어끼리 뭉쳐서 정렬 합니다. 즉, 내가 매번 잊어버리는 단어가 무엇인지, 얼마나 자주 잊어버리는지도 함께 파악 됩니다.
100개 모일 때 마다 뜻 만 보고 한자를 쓰기, 한자만 보고 발음과 뜻 쓰기 등 공부하면 됩니다. 읽고 쓰기가 가능하며 뜻도 다 알게 된 단어는 색을 바꾸거나 숨기기로 치우면 됩니다.
*피해야 할 방법.
보통은 비효율적으로 공부합니다. 예를 들면 残念와 残る는 모두 残 이라는 한자를 씁니다. 그래서 残이라는 한자를 공부할 때,
[ 残을 쓰고 발음은 'ざん' 이고 훈독은 のこす、のこる. 뜻은 잔인하다/남다 ]
라고 외웁니다. 이렇게 해서 2000자 넘는 상용한자 못 외우고, 외워도 실제 단어보면 헷갈려요. 제 방법대로 단어 단위로 외우는게 훨씬 낫습니다. 이는, 상용한자가 음독으로 쓰일때와 훈독으로 쓰일때의 연관성이 강하지 못 해서 입니다. 예를 들어 今日(きょう)라는 단어는, 今日라는 글자에 きょう라는 발음이 있는게 아닙니다. 일본에서 원래 '오늘'을 きょう 라고 발음 하다가, 한자가 들어오면서 今日라는 글자에 원래 쓰던 きょう를 붙여서 부르는 겁니다. 그러니, 단어단위로 외우지 않으면 나중에 훈독에서 완전 머리 터지게 될 겁니다.